GPT-5编程测评大反转!表面不及格,实际63.1%的任务没交卷,全算上成绩比Claude高一倍
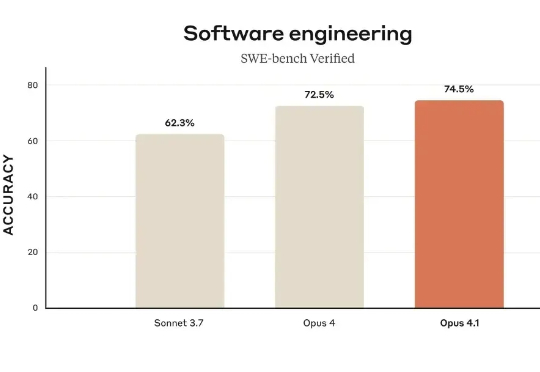
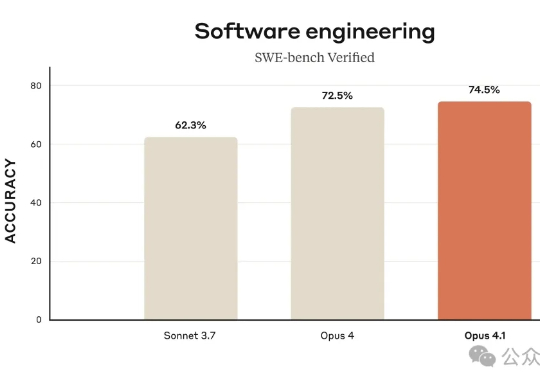
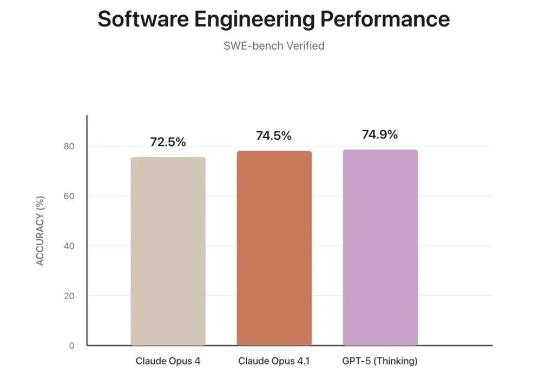
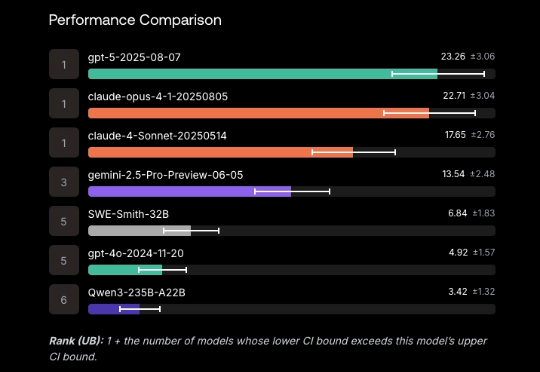
GPT-5编程测评大反转!表面不及格,实际63.1%的任务没交卷,全算上成绩比Claude高一倍Scale AI的新软件工程基准SWE-BENCH PRO,出现反转!表面上看,“御三家”集体翻车,没一家的解决率超过25%: GPT-5、Claude Opus 4.1、Gemini 2.5分别以23.3%、22.7%、13.5%的解决率“荣”登前三。
来自主题: AI技术研报
11125 点击 2025-09-22 16:11